
The Critical Need for Core DevOps and SRE Services
In today’s high-speed digital economy, reliability is the new currency. It’s not enough for systems to be fast—they must be dependable, scalable, and always-on. Traditional IT operations models are buckling under the pressure of digital expectations. This is where core DevOps and Site Reliability Engineering (SRE) services step in—not as optional enhancements but as fundamental pillars of modern digital transformation.
By uniting DevOps agility with the system dependability of SRE, companies are accelerating delivery and building resilience into their infrastructure. According to the 2023 DORA report, mature DevOps-SRE adopters deploy code 208 times more frequently, suffer 7 times fewer outages, and recover 2,600 times faster than their peers.
This blend of velocity and stability isn’t a passing trend—it’s an operational necessity.
Learn more about Hardwin’s DevOps services.
Understanding the Foundation of Core DevOps and SRE Services
Core DevOps Principles: Breaking Down Traditional Barriers
DevOps evolved as a strategic response to long-standing friction between rapid development and operational stability. As a result, the methodology revolutionized how teams build, test, and ship software by emphasizing automation, collaboration, and continuous feedback.
Key components include:
- CI/CD Automation: Continuous Integration and Continuous Deployment (CI/CD) pipelines enable organizations to deploy 46x more frequently. Moreover, automated testing boosts quality and accelerates go-to-market timelines.
- Infrastructure as Code (IaC): With IaC, infrastructure becomes version-controlled, repeatable, and error-resistant. Consequently, environment provisioning is reduced from hours to minutes.
- Cultural Transformation: DevOps dissolves silos, promoting shared accountability and innovation between dev and ops.
- Strategic Automation: By automating repetitive processes, teams save time and shift focus toward high-impact engineering efforts.
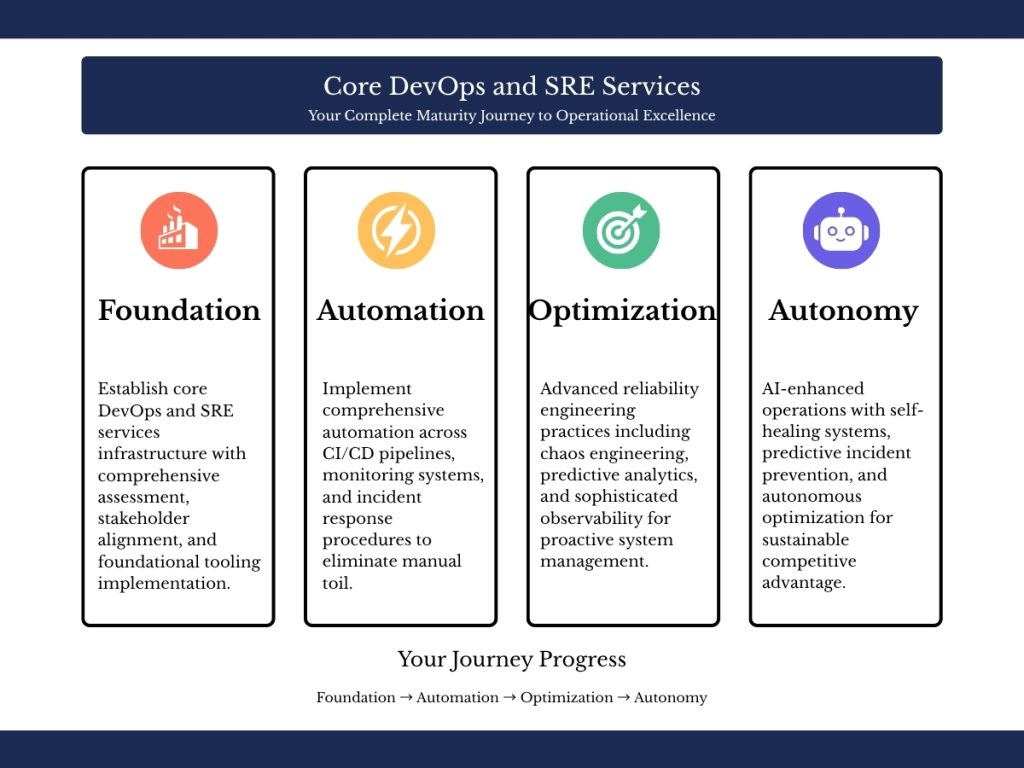
Site Reliability Engineering: Reliability Through Engineering Discipline
SRE builds upon DevOps by introducing software engineering rigor to operations. Originally developed at Google, SRE provides operational frameworks that enforce reliability.
Pillars of modern SRE include:
- Service Level Objectives (SLOs) and Service Level Indicators (SLIs) for setting measurable service expectations.
- Error Budgets to balance innovation velocity with system stability.
- Toil Reduction by automating manual, low-value tasks.
- Blameless Postmortems to enable faster innovation and institutional learning after incidents.
Together, DevOps and SRE create a dynamic system of proactive reliability and innovation.
Strategic Business Value of Core DevOps and SRE Services
Quantifiable Benefits That Drive ROI
High-performing tech teams are rewriting the rules of business growth:
- 973x faster deployment rates
- 6,570x faster lead times
- 3x lower change failure rates
- 27% higher job satisfaction for engineering teams
Organizations investing in core DevOps and SRE services also report:
- 20% increase in revenue growth
- 21% improvement in profitability
- Enhanced recruitment and retention, thanks to modern engineering cultures
According to McKinsey & Company, businesses with high DevOps maturity report a 30% decrease in time-to-market.
Competitive Advantages Through Operational Excellence
Beyond speed, DevOps and SRE deliver a strategic edge:
- Market Agility: Quickly respond to shifting customer demands and emerging trends.
- Innovation Acceleration: Spend less time fixing and more time inventing.
- Resilience and Risk Management: Downtime is no longer an acceptable risk. Moreover, automated recovery and proactive monitoring mitigate potential losses.
Next-Gen Capabilities of Core DevOps and SRE Services
AI-Driven Reliability Engineering
Artificial Intelligence (AI) is pushing SRE into predictive and autonomous territories:
- Predictive Incident Prevention through ML-powered early warning systems
- Root Cause Analysis using AI correlation across thousands of metrics
- Automated Resource Optimization balancing performance and cost
- Anomaly Detection for early alerts on unknown system behaviors
Security as a Built-In Reliability Principle
Modern core DevOps and SRE services treat security as reliability’s twin:
- Zero Trust Architectures ensure secure-by-design environments.
- Continuous Security Monitoring integrates threat detection into observability stacks.
- Automated Compliance Checks reduce audit fatigue and policy drift.
- Software Supply Chain Security strengthens third-party component trust.
Scaling Across Cloud and Edge
As businesses adopt hybrid and multi-cloud infrastructures, reliability becomes more complex:
- Cross-Cloud Observability ensures end-to-end visibility
- Global Load Balancing improves latency and availability
- Edge Reliability Strategies ensure local operations persist during central outages
- Hybrid Management Models maintain performance between on-prem and cloud systems
Measuring Success: Essential DevOps and SRE KPIs
To ensure your investment in core DevOps and SRE services delivers tangible results, you must track the right performance indicators. Without a clear understanding of what success looks like, even the most sophisticated tools or processes can fall short.
Fortunately, measuring the impact of DevOps and SRE is not guesswork. Instead, it involves a structured evaluation of technical efficiency, reliability, and business outcomes. Let’s explore the key metrics that define excellence.
Technical Performance Metrics: Speed and Stability Combined
First and foremost, DevOps and SRE success begins with technical performance. These metrics reveal how quickly and safely your team can ship code and recover from failures:
- Deployment Frequency: High-performing teams deploy multiple times per day, not just once a month. More frequent deployments also reduce batch size, making it easier to pinpoint and fix errors quickly.
- Lead Time for Changes: This refers to the time taken from committing code to getting it into production. Shorter lead times mean faster delivery and faster feedback loops from users.
- Change Failure Rate: Not all deployments go smoothly. This metric shows how many changes require immediate fixes or rollbacks. Lower failure rates indicate mature CI/CD pipelines and better quality assurance.
- Mean Time to Recovery (MTTR): When incidents occur, how fast can you recover? A low MTTR demonstrates effective alerting, response processes, and team readiness.
Service Reliability Metrics: Meeting User Expectations Consistently
Once you’ve optimized for technical velocity, it’s time to ensure your systems are actually reliable. These metrics highlight how well your services meet user expectations:
- SLO Achievement Rate: To begin with, your Service Level Objectives (SLOs) define what acceptable service performance looks like. Consequently, the percentage of time your system meets those goals serves as a clear, measurable indicator of reliability.
- Error Budget Consumption: In alignment with this, SRE practices allow for a certain level of error within your system. Therefore, by continuously monitoring how quickly you’re “spending” that error budget, teams can maintain a healthy balance between rapid innovation and operational risk.
- Mean Time Between Failures (MTBF): Similarly, this metric tracks how frequently your system experiences disruptions. As a result, a rising MTBF over time suggests that your infrastructure and operational processes are becoming more stable and resilient.
- Customer-Affecting Incident Reduction: Ultimately, reliability is measured through user experience. Thus, reducing outages and performance issues that impact end-users directly correlates with higher customer satisfaction and long-term retention.
Business Impact Metrics: Translating DevOps to Value
In addition to technical and operational insights, the most strategic DevOps and SRE metrics tie directly to business value. These KPIs demonstrate how your engineering efforts support growth and profitability:
- Customer Satisfaction Scores (CSAT or NPS): Reliable systems lead to happier customers. Measuring user sentiment provides a direct line of feedback on how system stability impacts experience.
- Revenue Protection and Growth: Outages are expensive. Quantifying the revenue lost during downtime—and the revenue gained through faster delivery—justifies further investment in DevOps and SRE capabilities.
- Engineering Productivity Gains: But how much time are your developers truly spending on innovation versus firefighting? Ultimately, increased productivity is a clear sign that your automation and reliability practices are not just in place—but actually working.
- Operational Cost Reduction: Automation and smarter infrastructure management often result in fewer human errors and lower overhead. These cost savings can then be reinvested into new features or innovations.
By connecting these metrics to your company’s bottom line, you not only justify the ROI of DevOps and SRE, but also make a compelling case for long-term investment in operational excellence.
Your Path to Operational Excellence Starts Now
The age of fragile systems and reactive operations is over. In contrast, core DevOps and SRE services have become the new baseline for any organization that is truly serious about performance, uptime, and customer trust.
Whether you’re scaling a SaaS product, running a global retail platform, or building enterprise-grade applications—your infrastructure strategy must be proactive, intelligent, and reliable by design.
Ready to Build Resilience at Scale?
At Hardwin Software, we specialize in designing custom DevOps and SRE roadmaps tailored to your growth goals. Whether you’re navigating cultural shifts, transitioning to cloud-native architecture, or embracing AI-powered automation, our experts are here to guide you every step of the way.
📩 Contact us to begin your transformation journey.
Let’s build the future of reliability—together.

