
Lakehouse architectures and open formats describe a modern data approach that blends the scalability and low cost of data lakes with the reliability and performance of data warehouses, so teams can run BI, AI/ML, and streaming on one platform without duplicating data. Because lakehouse architectures and open formats use open standards on cloud object storage, the platform achieves warehouse‑grade trust—like ACID transactions and time travel—while staying flexible and vendor‑agnostic for future needs.
Simple definition
A lakehouse is a unified data platform that stores data in open file formats on object storage and manages it with an open table format to deliver transactions, schema control, and versioning. In practice, this means analysts, data scientists, and engineers can all use the same tables, with consistent results, across multiple engines and clouds.
Why it exists
Traditional data lakes were cheap and flexible, but they lacked guarantees—so concurrent writes, broken schemas, and inconsistent reads caused headaches. Classic warehouses were strong on reliability and SQL performance, but they were costly, rigid, and not ideal for streaming or semi-structured data. The lakehouse resolves this tension by adding a transactional, metadata-rich table layer over open files in cheap storage.
What “open formats” really mean
Open formats have two layers:
- Open file formats: Columnar files like Parquet or ORC store the actual data efficiently.
- Open table formats: Metadata and transaction layers—such as Delta Lake, Apache Iceberg, and Apache Hudi—turn folders of files into reliable, queryable “tables” with ACID transactions, schema evolution, and time travel.
Because these formats are open and widely supported, teams avoid lock-in and can plug in multiple engines (Spark, Trino, Flink, serverless SQL) to the same table without copying data.
The key open table formats
- Delta Lake: Great for unifying batch and streaming with ACID guarantees, schema enforcement/evolution, and time travel, so pipelines stay consistent while data changes continuously.
- Apache Iceberg: Designed for very large tables with hidden partitioning, rich metadata, and snapshot isolation, so queries prune aggressively and plan faster at scale.
- Apache Hudi: Built for incremental processing and CDC, with upserts and near-real-time views, so freshness-sensitive analytics and operational data lakes work smoothly.
What’s new: unified platforms
What’s changed recently is that platforms increasingly support all three formats under one roof, so teams can choose the right format per workload and still interoperate. As a result, one table can often be consumed by multiple engines and clients without duplication, which reduces complexity, cost, and vendor lock-in.
Core benefits in plain language
- Reliability: ACID transactions prevent half-written data and race conditions, so dashboards don’t break during heavy writes.
- Performance: Rich metadata, file statistics, and partition evolution reduce scanned data and speed up planning, so queries run faster and cheaper.
- Governance: Time travel, audit history, and schema enforcement create trustworthy, reproducible analytics with cleaner investigations and audits.
- Flexibility: Open formats and catalogs keep data portable across engines and clouds, so architectural choices remain reversible.
How a lakehouse is built
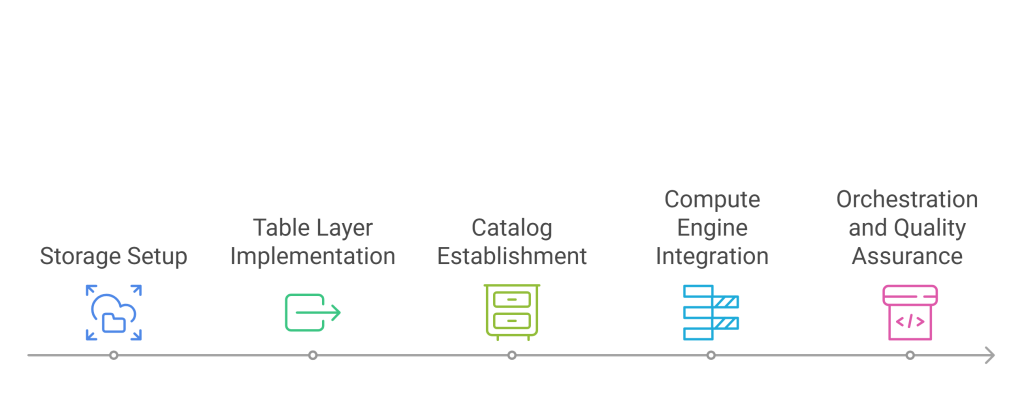
- Storage: Cloud object storage (e.g., S3/ADLS/GCS) with columnar file formats (e.g., Parquet) for low-cost, elastic capacity.
- Table layer: An open table format (Delta, Iceberg, or Hudi) that provides transactions, schema evolution, and time travel.
- Catalog: A central registry that tracks tables, schemas, partitions, and snapshots for consistent discovery and access control.
- Compute: Multiple engines—Spark, Trino, Flink, serverless SQL—sharing the same tables for diverse workloads.
- Orchestration and quality: Pipelines, data contracts, tests, and observability to keep deployments safe and data trustworthy.
When to choose which format
- Choose Delta Lake when combining batch and streaming into one consistent pipeline matters most, and when DML operations and versioning are central.
- Choose Apache Iceberg when very large analytic tables dominate, pruning matters, and hidden partitioning plus snapshot isolation can unlock big efficiency.
- Choose Apache Hudi when incremental upserts, CDC, and near-real-time data availability are primary, and row-level mutations at scale are routine.
Practical performance playbook
- Compact files to healthy target sizes so scans are efficient and task overhead stays low.
- Evolve partitions as query patterns change so pruning remains effective without rewrites.
- Use metadata and statistics to skip irrelevant files and speed up planning.
- Automate compaction, clustering, and vacuum routines so costs and latencies remain predictable.
Governance and security essentials
- Enforce schemas at write time so bad payloads can’t enter critical tables.
- Use time travel and audit logs to reproduce past states for compliance, RCA, and model explainability.
- Anchor policies to cataloged tables rather than file paths so access control is consistent across engines.
Cost control that lasts
- Reduce compute spend by pruning and compacting so queries scan less and finish faster.
- Avoid duplicate datasets across engines thanks to open formats, which keeps storage bloat in check.
- Maintain snapshot retention policies to balance auditability with storage efficiency.
Case study: Retail signals without replatforming
A national retailer needs real-time inventory visibility and reliable historical analysis for planning. The team standardizes on open formats with a shared catalog so point-of-sale events stream in as upserts while daily dimension enrichments run in batch. Because both streaming dashboards and forecasting models query the same tables, there’s no duplication and no conflicting definitions.
During holiday peaks, ACID transactions keep concurrent writes consistent so KPIs don’t flicker. As seasonal patterns shift, the team evolves partitions to match filters and compacts files to sustain low-latency queries. With time travel and snapshot histories, finance reproduces month-end states, and data science replays model training to explain drift. The outcome is faster decisions, fewer stockouts, cleaner audits, and no parallel warehouse to maintain.
Conclusion
A Lakehouse architectures and open formats brings together the best of lakes and warehouses by layering an open, transactional table format over low-cost, scalable storage so diverse workloads can thrive on the same source of truth. With ACID guarantees, rich metadata, and time travel, teams gain reliable analytics; with open formats and catalogs, they retain flexibility across engines and clouds. As unified platforms mature, this architecture turns reliability, performance, and governance into default settings—so data teams can build fast, adapt freely, and scale with confidence.
FAQs
What is a lakehouse in one sentence?
A lakehouse is a unified data platform that adds transactions, schema control, and time travel to open files on object storage so BI, AI/ML, and streaming can share the same trusted tables.
How do open formats help?
They separate data from compute, standardize table semantics, and keep data engine-agnostic so teams can switch tools without copying datasets.
Can one table serve multiple engines?
Yes, open table formats and catalogs expose the same table to different engines, which prevents duplication and lock-in.
Do lakehouses handle streaming and batch together?
Yes, table formats support incremental writes, upserts, and snapshot reads so streaming and batch pipelines can safely converge.
Why are governance and audits easier?
Time travel, schema enforcement, and audit logs create a verifiable history, so investigations are reproducible and compliance is demonstrable.

