
Cross-platform apps for robotics and automation help unify control, monitoring, and analytics across robots, PLCs, sensors, and cloud services, and, importantly, they do this across operating systems and device types without costly rewrites. Moreover, because the same app can run on iOS, Android, Windows, macOS, and Linux, teams accelerate releases while maintaining consistent UX and policy enforcement. Consequently, operations gain visibility, developers reduce rework, and executives see faster time to value.
However, despite the excitement, many leaders still ask how to balance performance, safety, maintainability, and real-time responsiveness when choosing a cross-platform approach. Therefore, this guide explains the foundations, lays out architecture patterns, compares framework choices, and demonstrates a practical case study with measurable outcomes. In addition, it closes with an implementation checklist, pitfalls to avoid, and concise FAQs so teams can move from idea to production with confidence.
What “cross-platform” means in robotics
At its core, cross-platform apps for robotics and automation abstract the presentation and orchestration layers so the same user workflows and APIs operate on multiple operating systems and form factors. Specifically, a shared codebase implements UI, state, business logic, and data contracts while native bridges and drivers handle low-level device access. As a result, the app can supervise a robot cell on a Windows HMI, push alarms to an Android handheld, display KPIs on an iPad, and feed events to a Linux edge gateway—all using one cohesive application. Furthermore, because the integration surface is standardized, security policies, audit trails, and change control become simpler to administer.
Key value propositions
Faster delivery: One codebase ships to many endpoints; therefore, releases become predictable, and QA cycles shrink.
Lower TCO: Shared components reduce duplicated work; consequently, maintenance and dependency updates cost less.
Consistent UX: Operators learn one interface; thus, onboarding improves, and error rates decline.
Interoperable data: Common APIs and schemas align robots, MES/SCADA, and cloud analytics; hence, data silos dissolve.
Future-ready posture: As devices evolve, portability limits rework; accordingly, upgrades become less disruptive.
Core architecture of Cross-Platform Apps for Robotics & Automation
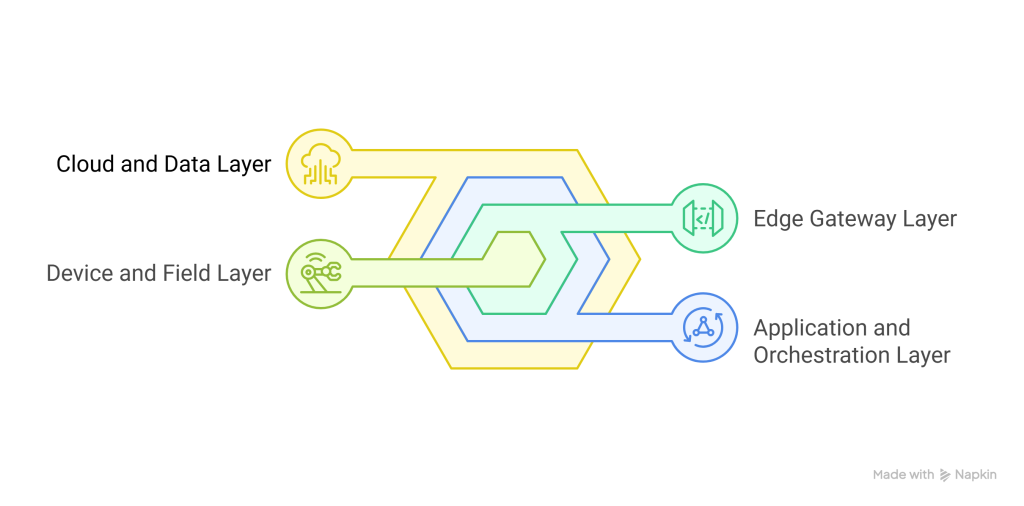
Because industrial automation has strict latency and safety constraints, architecture matters. Therefore, consider a layered approach:
Device and field layer: Robots, PLCs, sensors, AGVs, and vision systems expose data via standard protocols, and, where needed, vendor SDKs extend capabilities.
Edge gateway layer: Lightweight services run at the cell or site to buffer streams, enforce QoS, perform local AI inference, and persist time-series data, so real-time decisions do not depend on WAN reliability.
Application and orchestration layer: The cross-platform app implements role-based interfaces, workflows, and command sequences; meanwhile, it communicates through secure APIs to edge services and cloud platforms.
Cloud and data layer: Central services handle identity, fleet registry, digital twins, model training, and long-term analytics; moreover, they coordinate configuration-as-code and policy rollout.
Critically, this pattern separates deterministic control loops—which stay at the edge or controller—from human-in-the-loop supervision, which can tolerate slightly higher latency. In effect, hard real-time remains local, while the app provides unified visibility, command, and analytics across endpoints.
Essential capabilities to include
Because industrial contexts are demanding, cross-platform apps for robotics and automation should include the following:
Role-based access control: Operators, maintainers, and supervisors need tailored views and permissions; consequently, access must reflect safety rules and segregation of duties.
Secure offline mode: Edge-local caches allow critical workflows during network outages; therefore, work does not stall when connectivity fails.
Event streaming and buffering: Alarms, telemetry, and video frames should be streamed efficiently; moreover, lossless backfill prevents data gaps.
Command queueing with acknowledgments: When sending job commands or parameter updates, the app must track state transitions and confirmations; hence, operators trust what the UI displays.
Digital twin mapping: Logical models of robots and cells simplify navigation, simulation, and what-if analysis; as a result, teams plan safely before applying changes.
Predictive maintenance: Built-in models detect drift, vibration anomalies, and thermal patterns; consequently, unplanned downtime drops.
Audit trails and e-signatures: Regulated industries require traceability; therefore, every change needs provenance, timestamps, and user identity.
Policy packs and configuration-as-code: Templates push standard settings to sites; thus, compliance improves and variance decreases.
Extensibility via plugins: Partners and integrators can add adapters and dashboards; accordingly, ecosystems thrive without forking the core app.
Framework choices and when to use them
Although no single framework fits all, several patterns repeat:
.NET MAUI/Xamarin
When an enterprise already uses C# and .NET across backend, HMI, and Windows industrial PCs, .NET MAUI provides strong native integration and long-term maintainability. Moreover, it compiles to iOS, Android, Windows, and macOS, while sharing business logic libraries with server-side services. Consequently, regulated organizations that value Microsoft’s tooling often prefer this route.
Flutter
Because Flutter renders with a high-performance engine and offers precise, consistent UIs, it is ideal for operator panels, mobile HMIs, and complex dashboards that must feel the same across devices. Furthermore, its reactive model supports real-time widgets, and its desktop and web targets enable broad reach. Therefore, teams prioritizing UX parity and speed of iteration increasingly choose Flutter.
Progressive Web Apps (PWA)
For read-mostly dashboards and light control tasks, PWAs reduce installation friction and update overhead. Nevertheless, when robust offline storage, hardware features, or demanding graphics are required, a compiled framework is usually preferable.
React Native
If teams already rely on React for web apps, React Native lowers learning curves and allows shared patterns. Additionally, a rich ecosystem of libraries exists, and TypeScript strengthens safety. However, for graphics-heavy HMIs or tight real-time visuals, Flutter may feel smoother; consequently, a pilot is recommended before committing.
Native plus shared core
In situations with extreme hardware integration or vendor-specific SDKs, native shells (Swift/Kotlin/C#/C++) can wrap a shared core for models, messaging, and UI components. Thus, teams keep portability without sacrificing specialized device access.
Communication and protocol strategy
Because heterogeneity is the norm, protocol breadth matters:
OPC UA for industrial interoperability and secure data modeling.
MQTT for lightweight pub/sub telemetry and command topics across unreliable links.
gRPC/REST for structured APIs between app, edge, and cloud.
ROS/ROS 2 for robotics middleware, node graphs, and standardized message types.
Vendor SDKs for specialized motion control, vision tuning, and safety I/O.
Importantly, choose one canonical event schema and enforce it through adapters; therefore, downstream analytics remain consistent even as upstream devices vary. In addition, version the schema and provide deprecation windows so integrators can plan upgrades safely.
Security by design
Given the stakes, security cannot be bolted on later. Therefore, adopt these principles early:
Zero trust networking: Mutual TLS, short-lived tokens, and least-privilege scopes by device and user.
Secrets management: Hardware-backed keystores on devices and centralized vaults in cloud; consequently, credentials avoid code and config files.
SBOM and signed artifacts: Produce a software bill of materials and sign builds; thus, supply chain risk is reduced.
Policy-as-code: Encode RBAC, approval flows, and geofencing rules so changes are reviewable and testable.
Continuous validation: Pen tests, fuzzing on protocol parsers, and attack-surface reviews scheduled each sprint.
Performance and real-time considerations
Because robotics is time-sensitive, treat the app as an orchestrator while reserving hard real-time for controllers and edge components. Consequently, apply these patterns:
Coalesce UI updates with animation frames to avoid jitter on dashboards.
Use backpressure-aware streams for video and telemetry so bursts do not freeze the UI.
Cache recent state locally to keep panels responsive even when the network fluctuates.
Prefer binary protocols for high-frequency data while exposing human-friendly summaries for operators.
Data, analytics, and digital twins
To maximize value, design data flows intentionally:
Time-series storage at the edge for fast local queries and compact retention policies; thus, technicians can diagnose without WAN dependency.
Batch export and stream mirroring to the cloud for fleet-wide analytics; therefore, corporate dashboards stay current.
Digital twin graphs linking assets, locations, jobs, and alarms for contextual reasoning; accordingly, predictive models gain richer features.
MLOps pipeline that retrains models from labeled incidents and ships updates over-the-air with staged rollouts; hence, model drift is controlled.
Operator experience and human factors
Because adoption hinges on usability, obsess over operator workflows:
Provide one-tap actions for common mitigations, and, importantly, require confirmations for safety-critical steps.
Offer color-safe palettes and high-contrast modes because many facilities have harsh lighting.
Include guided tours and embedded micro-lessons so new hires learn in context.
Localize critical alerts and include pictograms so mixed-language teams act quickly.
Implementation roadmap (12 weeks example)
While timelines vary, the following milestone-driven plan keeps momentum:
- Weeks 1–2: Scope key processes, inventory devices, define target roles, and lock the canonical schema so downstream churn stays minimal.
- Weeks 3–4: Build a vertical slice with authentication, a live telemetry panel, and one robot cell, giving stakeholders visible value early.
- Weeks 5–6: Introduce command workflows, enable a secure offline cache, and configure alarm routing with acknowledgments to make the app production-ready.
- Weeks 7–8: Integrate with MES/CMMS, stand up digital twins, and connect predictive features so maintenance teams gain timely foresight.
- Weeks 9–10: Strengthen security controls, implement comprehensive audit trails, and finalize role-based experiences to satisfy governance requirements.
- Weeks 11–12: Pilot at a single site, capture KPIs, resolve edge cases, and prepare a staged rollout so scaling becomes reliable and repeatable.
Case study: Automotive assembler unifies global robot fleet
A multinational automotive assembler operated 14 plants with mixed vendors and OS stacks, which, unsurprisingly, led to fragmented HMIs, inconsistent procedures, and extended downtime during failures. Moreover, updates required plant-by-plant coordination, and training content diverged quickly, causing confusion.
Solution
The company built cross-platform apps for robotics and automation using Flutter for the operator UI, Rust services at the edge for deterministic buffering, and a .NET backend for identity, fleet registry, and policy. Furthermore, it standardized on MQTT for telemetry, OPC UA for controller data, and gRPC for the app-to-edge command plane. In addition, the team implemented digital twins for every cell and added policy-as-code for approvals and e-signatures.
Outcomes
48% faster incident acknowledgment thanks to unified alarms, richer context, and one-tap mitigations.
36% reduction in unplanned downtime after deploying vibration and thermal anomaly models with staged, over-the-air updates.
31% lower training time for new operators because the UX and procedures were consistent across devices and plants.
Two-week average rollout for new features globally due to one codebase and automated compliance testing.
Notably, safety incidents dropped as well because risky commands demanded explicit justifications and dual approvals. Consequently, operations, quality, and safety teams aligned around a single source of truth.
Common pitfalls and how to avoid them
Overloading the app with hard real-time logic: Keep deterministic control at the controller or edge; therefore, UI remains responsive and safe.
Skipping schema governance: Without a canonical schema, integrations multiply inconsistently; thus, analytics degrade and testing explodes.
Treating offline as an edge case: Plan for it from day one; accordingly, crews keep working in dead zones.
Underinvesting in observability: Add tracing, metrics, and log correlation in both app and gateways; hence, MTTR improves dramatically.
Ignoring human factors: Crowded screens and unclear alerts cause mistakes; therefore, prioritize clarity and confirmation flows.
Testing strategy for reliability
Because industrial stakes are high, adopt a layered test approach:
Contract tests for protocol adapters so each device integration stays stable across updates.
Synthetic telemetry generators for load and chaos tests; thereby, buffering and backpressure policies are validated.
Hardware-in-the-loop rigs for critical cells so command sequences and safety interlocks are verified.
Usability studies with operators in real environments; therefore, real-world ergonomics shape decisions.
Governance, compliance, and audits
Industries like automotive, medical devices, and food processing require strict governance. Therefore:
Capture immutable audit logs for commands, configuration changes, and approvals.
Map controls to frameworks such as ISO 27001, IEC 62443, and SOC 2 where applicable.
Run periodic access reviews and key rotations so entitlement drift is caught early.
Maintain a SBOM and vulnerability scanning for every release; consequently, security posture stays current.
Cost modeling and ROI
To persuade sponsors, quantify benefits explicitly:
Engineering cost avoidance from a single codebase and shared libraries across platforms.
Reduced downtime via predictive alerts and faster acknowledgment workflows.
Lower training overhead due to consistent UX and embedded micro-lessons.
Fewer site visits as remote diagnostics and guided procedures resolve issues quickly.
Because these savings compound at fleet scale, the payback period often arrives within 9–18 months, after which savings become structural.
Future trends shaping the space
Adaptive UX with multimodal inputs: Voice, gestures, and wearables augment touch, so hands-free tasks become practical on noisy floors.
Vision-driven autonomy at the edge: On-device models provide robust inspection and alignment even with variable lighting.
Privacy-preserving analytics: Federated learning and on-device feature extraction reduce data movement and compliance burdens.
Composable robotics: Vendors expose standardized modules, and, as a result, apps orchestrate fleets like microservices, not monoliths.
Practical checklist before coding
Define the primary user journeys and safety interlocks first, because UI will grow around these.
Choose a canonical data model and versioning strategy, so integrations remain sane.
Decide on the edge responsibilities, since latency and offline dictate design choices.
Select a framework aligned with team skills and UX needs; consequently, ramp-up time drops.
Establish CI/CD with signing, SBOM, and staged rollouts, so reliability increases from day one.
Create a pilot plan with success metrics, because early wins build momentum and sponsorship.
Actionable first steps this week
Inventory devices, protocols, and critical alerts, then prioritize one high-value cell for a vertical slice.
Stand up an edge gateway with buffering and authentication, and wire one robot source of truth.
Ship a minimal cross-platform UI that shows live telemetry, acknowledges alarms, and supports offline view.
Capture operator feedback in the first 48 hours, and iterate quickly to build trust.
FAQs
What are cross-platform apps for robotics and automation?
They are applications that run on multiple operating systems and devices while providing a unified experience for robot supervision, command, data collection, and analytics; moreover, they standardize APIs and workflows so teams deliver features faster and maintain them more easily.
Why choose a cross-platform approach over native-only HMIs?
Because a single codebase reduces cost, increases release velocity, and ensures consistent UX and security across endpoints, organizations avoid duplicated efforts and minimize variance between sites; therefore, adoption improves and errors fall.
Which framework is best for industrial-grade solutions?
If teams prefer C# and enterprise tooling, .NET MAUI often fits well; if pixel-perfect, high-performance UIs across desktop, mobile, and web are critical, Flutter excels; if JavaScript/TypeScript skills dominate, React Native provides leverage; consequently, the “best” depends on skills, device breadth, and UX needs.
How do these apps handle real-time constraints safely?
Deterministic control loops remain on controllers or edge services, while the cross-platform app focuses on orchestration, visibility, and human-in-the-loop commands; therefore, latency-sensitive operations stay safe, and the UI remains responsive.
How can teams start without risking production?
Begin with a vertical slice for one cell, choose a minimal protocol set, and pilot with friendly users; then, expand to additional cells after collecting metrics on acknowledgment time, downtime reduction, and training improvements, so scaling decisions rest on evidence.

