
Cloud-Native & Multi-Cloud Strategies: The Backbone of Digital Transformation is not a slogan; rather, it is a pragmatic blueprint for building agile, resilient, and innovation-ready digital businesses. Because cloud-native architectures accelerate delivery while multi-cloud choices reduce lock-in and risk, organizations can modernize faster and compete more effectively. Consequently, teams ship value sooner, adapt continuously, and align technology with measurable outcomes.
Why cloud-native matters
Speed, agility, and continuous delivery
Cloud-native emphasizes modular microservices, containerization, and automated CI/CD, so product teams iterate quickly and reduce release risk. Moreover, the architectural decoupling allows independent scaling and safer deployments, which shortens feedback loops and boosts innovation velocity. Therefore, businesses translate ideas into production features with less rework and fewer dependencies.
Reliability and resilience by design
Because cloud-native uses patterns like health checks, autoscaling, circuit breakers, and graceful degradation, systems remain dependable under pressure. Additionally, immutable infrastructure and declarative configs minimize configuration drift and recovery time. As a result, services sustain consistent customer experiences even during peak demand or failure events.
Developer productivity and platform engineering
As platform teams standardize golden paths and internal developer platforms, engineers gain paved roads for consistent, secure delivery. In addition, shared templates, baked-in observability, and policy-as-code reduce cognitive load and shadow variations. Consequently, teams focus on business logic instead of boilerplate, thereby raising throughput and quality.
Why multi-cloud matters
Avoiding vendor lock-in
A deliberate multi-cloud approach preserves negotiating power and architectural freedom, because workloads can move to the best-fit provider over time. Furthermore, portable building blocks—containers, Kubernetes, Terraform, and open APIs—shrink switching costs dramatically. Hence, organizations choose services based on merit, not inertia.
Resilience and locality
Placing workloads across providers and regions reduces correlated failure risk, while closer proximity lowers latency for key markets. Likewise, running active-active or active-passive topologies across clouds mitigates outage impact and speeds recovery. Thus, customer-facing applications become more dependable across geographies.
Regulatory and data-sovereignty alignment
Since jurisdictions increasingly restrict data movement, multi-cloud helps align storage and processing with regional laws. Moreover, policy-driven placement ensures sensitive workloads remain compliant without stalling global expansion. Therefore, enterprises scale internationally while respecting privacy and residency mandates.
Cloud-native plus multi-cloud: Stronger together
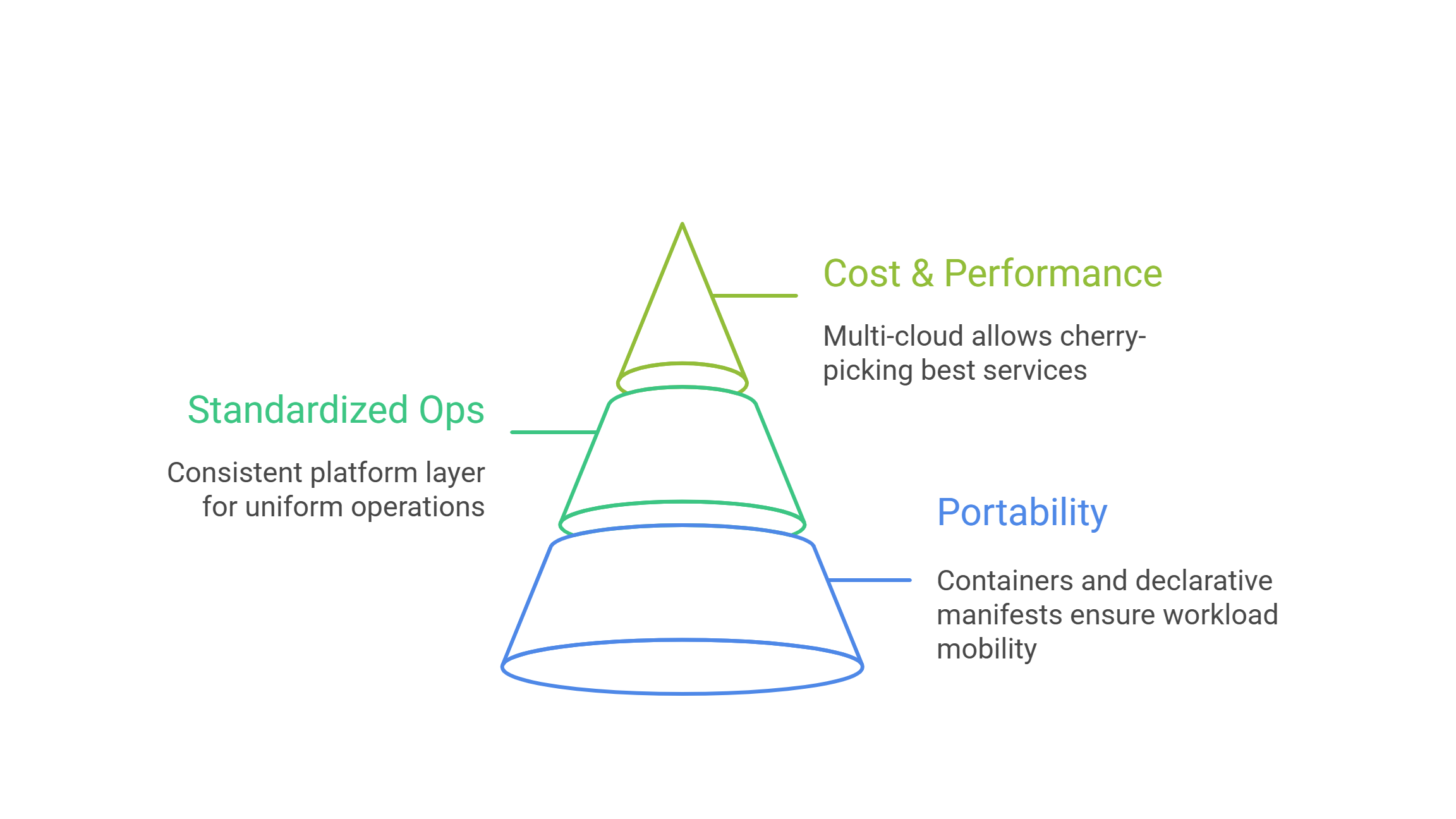
Portability as a first principle
Because cloud-native favors containers, service meshes, and declarative manifests, workloads become inherently portable. Additionally, this portability unlocks multi-cloud mobility for performance, price, and compliance optimization. Consequently, the architecture evolves without costly rewrites.
Standardized ops, diverse infrastructure
A consistent platform layer—GitOps, Kubernetes, IaC, and observability—enables uniform operations over heterogeneous clouds. Likewise, policy-as-code enforces security baselines everywhere, even as services vary by provider. Therefore, teams gain a single operating model across many substrates.
Cost, performance, and innovation arbitrage
Since each cloud excels in certain services, multi-cloud lets teams cherry-pick best-of-breed capabilities. Moreover, workload placement can shift to exploit pricing changes, specialized accelerators, or regional advantages. Hence, businesses continuously optimize for both value and differentiation.
Architecture fundamentals
Containers, orchestration, and service mesh
Containers ensure consistency; Kubernetes orchestrates scheduling, scaling, and rollout strategies; service meshes add traffic policies, MTLS, and resilience. Furthermore, sidecar or ambient mesh models centralize cross-cutting concerns without code changes. Therefore, teams standardize runtime behavior across clouds.
Event-driven and API-first design
Because event streams decouple producers and consumers, systems scale elastically and fail gracefully. Additionally, API-first governance enforces contracts that stabilize integrations across teams and vendors. Consequently, migrations and expansions become incremental, not disruptive.
Data architecture and gravity
Data’s “gravity” shapes design: tier storage, apply CDC pipelines, and use federated queries to avoid monoliths. Moreover, distributed caches and regional replicas reduce latency while respecting residency constraints. Thus, analytics and AI remain performant and compliant.
Security, governance, and compliance
Shift-left and zero trust
Security scans in CI, signed artifacts, and SBOMs catch risks before deployment, while zero-trust networking authenticates every hop. In addition, short-lived credentials and workload identity close gaps caused by static secrets. Therefore, runtime surfaces shrink and audit trails strengthen.
Policy-as-code and guardrails
OPA/Rego or equivalent policies enforce cluster, network, and pipeline rules automatically. Likewise, admission controls reject noncompliant resources, and drift detection reconciles desired state. Consequently, governance becomes continuous, not periodic.
Data protection and residency
End-to-end encryption, tokenization, and field-level controls protect sensitive data in motion and at rest. Moreover, fine-grained data catalogs and lineage satisfy audit requirements across providers. Hence, compliance becomes a design property rather than a bolt-on.
Operations and SRE in a multi-cloud world
Observability everywhere
Unified tracing, metrics, and logs—plus SLOs and error budgets—bring clarity across clouds and regions. Additionally, topology-aware dashboards, synthetic tests, and golden signals catch issues early. Therefore, incident response accelerates and postmortems improve systemic reliability.
GitOps and immutable delivery
Declarative repos define environments, pipelines reconcile drift, and rollbacks become instant via previous commits. Likewise, promotion across environments stays consistent because manifests, policies, and secrets travel together. Consequently, releases become safer and more frequent.
Capacity, performance, and FinOps
Rightsizing, autoscaling, and scheduled scaling align capacity with real demand, while unit economics guide placement. Moreover, anomaly detection and chargeback foster accountability among product teams. Thus, cost becomes an engineering signal, not just an invoice.
Data, AI/ML, and edge alignment
AI-ready foundations
Feature stores, model registries, and portable inference runtimes allow ML to run close to data or users. Additionally, GPU scheduling and spot orchestration balance performance and cost for training and serving. Therefore, teams scale AI confidently across clouds.
Edge and near-edge patterns
Because latency-sensitive use cases benefit from edge nodes, federated architectures push compute nearer to events. Moreover, asynchronous sync and conflict resolution keep central systems authoritative. Consequently, experiences remain responsive even with intermittent connectivity.
Trustworthy AI and governance
Model lineage, bias testing, and drift detection guard against silent degradation. Likewise, ethics reviews and human-in-the-loop workflows control sensitive decisions. Hence, AI remains compliant, reliable, and aligned with outcomes.
Migration and modernization roadmap
Assess, segment, and sequence
Start by inventorying applications, dependencies, and SLAs; then segment into rehost, replatform, refactor, or retire. Furthermore, prioritize high-impact, low-risk candidates to build momentum. Consequently, value arrives early while risk stays bounded.
Build the platform, then the products
Establish landing zones, identity, networking, secrets, and observability before mass migration. Additionally, offer golden templates and paved paths that encode best practices. Therefore, product teams deliver safely from day one.
Evolve via feedback and SLOs
Use SLOs to steer investments in resilience, latency, and cost, while blameless postmortems surface systemic fixes. Moreover, platform backlog intake ensures the runway keeps pace with product needs. Thus, modernization compounds rather than stalls.
Common pitfalls and how to avoid them
Accidental complexity
Layering tools without a platform vision creates expensive sprawl. Instead, converge on opinionated standards and automate with IaC and GitOps. Consequently, the stack remains coherent and operable.
Cloud-only without cloud-native
Simply relocating VMs misses elasticity and resilience benefits. Therefore, refactor the critical path to microservices and managed services where justified. As a result, outcomes improve beyond mere hosting changes.
Policy lag and security drift
If controls trail deployments, risk grows silently. Hence, enforce guardrails in pipelines and admission controllers, not just documents. Consequently, compliance becomes continuous.
Case study: Global fintech builds cloud-native multi-cloud backbone
Context and challenge
A global fintech needed sub-200ms latency for payments across three continents while meeting data residency rules and achieving 99.99% availability. Because a single-cloud setup caused regional latency spikes and compliance friction, growth targets were at risk.
Solution and architecture
The team adopted containers and Kubernetes with a service mesh for secure cross-cloud communication. Moreover, GitOps managed multi-cluster deployments, and a global control plane enforced policies. Data tiers combined regional write leaders, read replicas, and event streaming for reconciliation. Consequently, workloads ran near users while sensitive data stayed in-region.
Operations and outcomes
With SLOs and synthetic probes per region, the fintech detected issues within minutes and failed over automatically. Additionally, FinOps dashboards guided workload placement to exploit price-performance sweet spots. Therefore, latency dropped 35–60% regionally, availability exceeded targets, and compliance audits passed without remediation. Finally, the company launched new markets faster due to portable, policy-governed workflows.
People, process, and culture
Product thinking and outcome KPIs
Tie initiatives to business KPIs—conversion, churn, latency, cost per transaction—so trade-offs are explicit. Moreover, empower teams with budgets and SLOs to own outcomes. Consequently, platform and product priorities stay aligned.
Enablement over enforcement
Internal platforms should feel like products—self-service, documented, observable—rather than gatekeeping. Additionally, office hours, templates, and sandboxes accelerate adoption. Thus, standards spread through usefulness, not mandates.
Skills and continuous learning
Because clouds and tools evolve quickly, continuous learning paths keep teams current. Likewise, rotating on-call and postmortems spread operational wisdom. Therefore, resilience becomes a team habit.
Conclusion
Cloud-Native & Multi-Cloud Strategies: The Backbone of Digital Transformation is a practical, durable path to speed, resilience, and choice. Because portability, policy, and platform engineering reinforce one another, organizations reduce risk while increasing innovation capacity. Therefore, leaders who invest in a coherent platform, consistent guardrails, and outcome-driven culture will ship faster today and adapt smarter tomorrow.
FAQ
What’s the difference between cloud-native and multi-cloud?
Cloud-native is an application approach that uses containers, microservices, CI/CD, and declarative automation to deliver software quickly and reliably.
Multi-cloud is an infrastructure strategy that runs workloads across more than one cloud provider to improve resilience, reduce lock‑in, and optimize cost-performance.
Why combine cloud-native with a multi-cloud strategy?
Cloud-native makes apps portable and automatable; multi-cloud provides choice and resilience.
Together, they enable faster delivery, regional performance, regulatory alignment, and the ability to pick best‑of‑breed services without long-term lock‑in.
What core technologies are needed to get started?
Containers and Kubernetes for portability and orchestration.
GitOps, Infrastructure as Code, and policy‑as‑code for consistent, auditable operations.
A service mesh for secure, resilient service-to-service communication.
Centralized observability (traces, metrics, logs) and SLOs for reliability.
How can costs be controlled across multiple clouds?
Implement FinOps: rightsize resources, use autoscaling and scheduling, and track unit economics (e.g., cost per transaction).
Leverage committed-use discounts where appropriate, and move specific workloads to the most cost‑effective region or provider based on performance needs.

