
AI accelerating Azure is more than a headline; it is a compounding trend that changes how organizations plan budgets, architect systems, secure data, and measure product value. Because foundation models run close to enterprise data, platform consumption rises across compute, storage, and networking. Consequently, copilots embedded in productivity and security suites deepen adoption and spur additional cloud workloads. Moreover, partner solutions packaged for the marketplace shorten time to value, while governance add‑ons expand spend in areas that executives already prioritize. Therefore, leaders who treat AI as a portfolio—buying what de‑risks and building what differentiates—capture outsized returns without runaway costs, reinforcing AI accelerating Azure across the stack.
How “AI Accelerating Azure” Becomes a Flywheel
Although the narrative sounds broad, the mechanics are concrete. In practice, AI accelerating Azure emerges as models, data, and users converge on one platform.
Model access fuels consumption
Organizations host chat, vision, code, and agent models behind managed endpoints. Consequently, GPU/CPU usage, autoscaling groups, and traffic routing all increase.
Fine‑tuning, domain adaptation, and tool use add training data pipelines and monitoring layers. Therefore, storage and logging expand alongside inference.
Retrieval brings data gravity to the cloud
RAG (retrieval‑augmented generation) performs best near lakes, warehouses, and document stores. Consequently, teams co‑locate embeddings, indices, and governance in the same regions to reduce latency and egress.
Furthermore, once teams move one knowledge domain, adjacent domains follow, which strengthens the data network effect.
Copilots multiply SaaS value
AI assistants inside productivity, analytics, DevOps, and security tools improve time‑to‑insight and time‑to‑resolution. As a result, user satisfaction and stickiness rise, which, in turn, pulls more data to the platform.
Security and compliance create necessary upsell
AI extends the need for key management, DLP, safe prompting, and incident response to new workloads. Therefore, organizations spend where auditability and risk posture matter most.
Partner ecosystem accelerates vertical outcomes
ISVs deliver pre‑integrated domain AI on the same cloud identity and data rails. Consequently, customers adopt specialized capabilities without first building scaffolding.
How AI Accelerates Azure in Daily Team Workflows
- Faster build cycles, because managed endpoints and SDKs remove boilerplate.
- Larger datasets near apps, because retrieval and training prefer local data.
- Growth in cross‑service usage, because identity, security, and observability attach naturally.
- Pressure on budgets, because pilots begin spiky and then settle only after optimization.
What This Means for Engineering
Build vs. buy with intent
- Buy what is undifferentiated but operationally hard: model hosting, vector databases, content filters, evaluation, and observability. Consequently, teams move faster without reinventing infrastructure.
- Build where the moat lives: domain retrieval over your corpus, workflow orchestration, tool‑driven agents aligned to systems of record, and the UX that earns trust.
Architect for retrieval first
- Most enterprise wins come from better documents and better retrieval, not just bigger models. Therefore, prioritize ingestion quality, chunking, metadata, and access controls before scaling prompts.
- Additionally, evaluate precision/recall for retrieval sets and treat those metrics as first‑class citizens in CI.
Optimize latency, throughput, and cost together
- Stream partial tokens to reduce perceived latency; batch compatible requests; cache prompts and results; reuse embeddings across features. Consequently, users feel speed while finance sees stability.
- Route simple tasks to small models and reserve premium models for complex completion or reasoning. Therefore, cost per outcome drops without harming quality.
Bake evaluation into the pipeline
- Track groundedness, hallucination rate, exact‑match correctness where applicable, and user feedback. Promote models and prompts only when thresholds are met. Moreover, keep a regression budget so quality never slips silently.
Design for multi‑model, multi‑vendor
- Abstract providers behind interfaces; store prompts and tools as code; log inputs, outputs, and token counts; and keep fallback policies. Consequently, teams avoid single‑vendor outages and sudden price shocks.
What This Means for Data Leaders
Raise the bar on data quality and permissions
- RAG shines a light on stale, duplicate, and sensitive content. Therefore, implement lifecycle policies, deduping, PII detection, and row/column‑level access before you index.
- Moreover, enforce “need‑to‑see” in retrieval so results respect user entitlements.
Treat vector search as core data infrastructure
- Plan index capacity, retention, and rebuilds. Snapshot indices and version embeddings when models change dimensionality or provider. Consequently, you avoid subtle regressions that are painful to debug.
Unify lineage from raw data to model response
- Track the chain: source file → chunk → embedding → retrieval set → response. Because this lineage exists, audits, right‑to‑be‑forgotten, and root‑cause analysis become straightforward.
Instrument value, not only tokens
- Map features to business outcomes: deflection rates, handle time, activation, revenue influence, or cycle‑time reduction. Consequently, AI investments become comparable to other initiatives, which clarifies priorities.
What This Means for Security and Compliance
Extend least privilege to AI retrieval
- Propagate user identity into retrieval paths and restrict results accordingly. Additionally, apply redaction at ingestion or at query time for fields with sensitivity.
Build safety in the request path
- Pre‑filters and policy checks prevent risky prompts; in‑flight moderation and tool guards block sensitive actions; and post‑response validators catch errors before users see them. Therefore, incidents reduce without slowing development to a crawl.
Log deeply and retain wisely
- Capture prompts, retrieved chunks, model versions, outputs, and side effects. Hash or tokenize where appropriate; set retention by data class. Consequently, forensics improve while privacy stays intact.
Manage third‑party model risk
- Keep a model and tool registry that records provider, version, eval scores, intended use, and restrictions. Gate rollouts behind feature flags and re‑evaluate on upgrades. Therefore, you align with internal risk frameworks.
What This Means for Finance and FinOps
Expect a spike, then a plateau
- Pilots create bursts as experiments iterate; production flattens when caching, routing, and cheaper models replace naive defaults. Therefore, approve budgets with an explicit optimization phase.
Create guardrails early
- Quotas per team and app, token ceilings per request, model allowlists, and mandatory caching. Additionally, alert on spend per feature, not only per subscription. Consequently, teams self‑correct before bills surprise.
Measure value per currency unit
- Tie spending to solved tickets, minutes saved, deals influenced, or verified revenue. Kill low‑ROI features quickly and double down where the return is clear.
A Practical Reference Architecture (High Level)
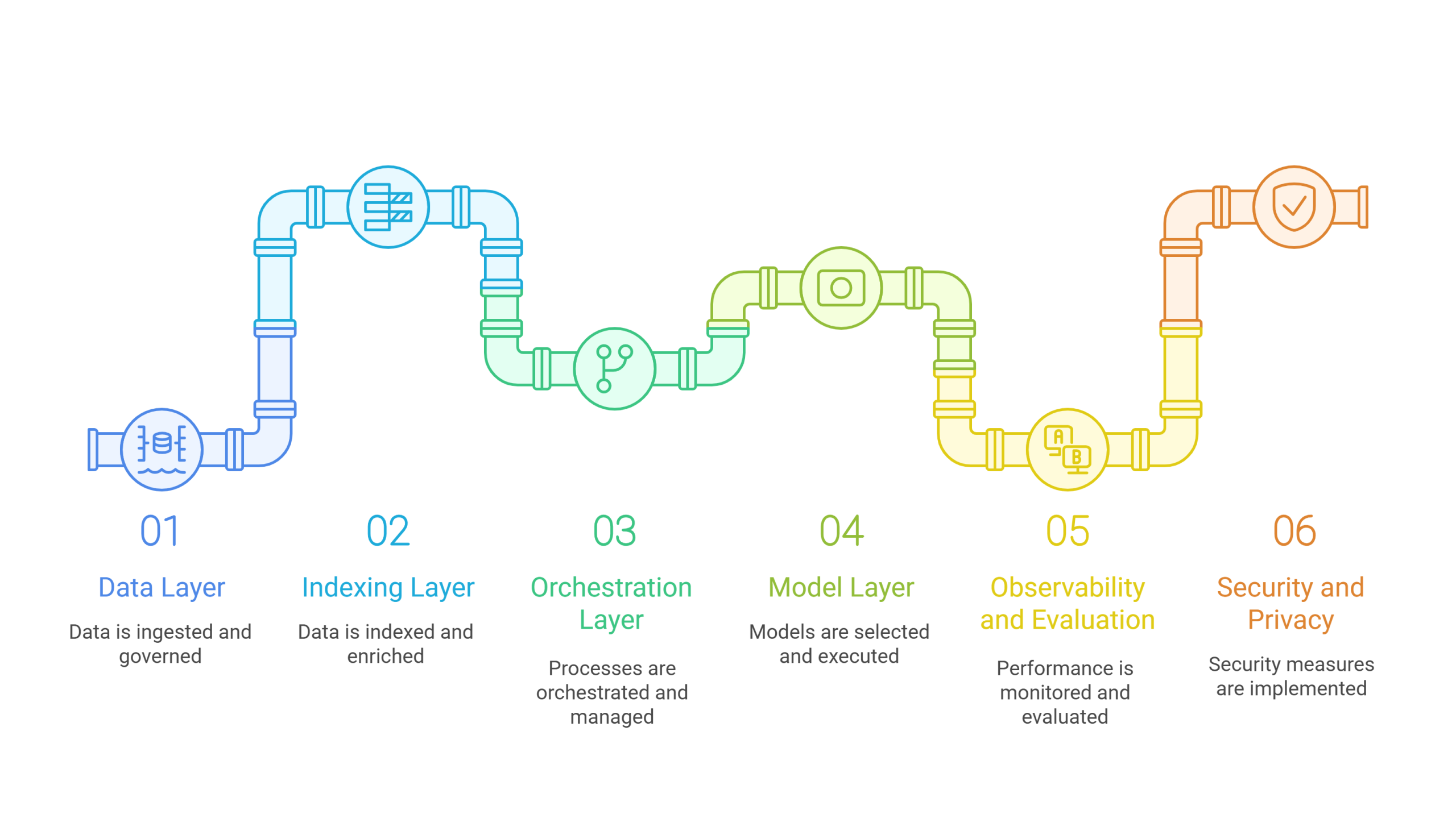
- Data layer
- Lake/warehouse for structured analytics, document stores for unstructured content, and streaming for freshness. Because governance belongs here, apply access controls and lineage at ingestion.
- Indexing layer
- Chunking, metadata enrichment, embeddings, and a vector database with ACL‑aware retrieval. Consequently, results reflect both relevance and permissions.
- Orchestration layer
- Prompt templates, callable tools/functions, policy and moderation guards, and a router that selects models and fallbacks. Therefore, runtime becomes predictable and debuggable.
- Model layer
- A mix of hosted frontier models for complex reasoning and efficient open models for classification, routing, and summarization. Batch endpoints handle offline jobs and nightly workflows.
- Observability and evaluation
- End‑to‑end tracing for requests and tokens, dashboards for quality metrics, and an A/B harness for prompts, retrieval strategies, and model choices.
- Security and privacy
- Identity propagation, encryption, DLP, KMS for keys, secret management, and audit trails with rational retention.
Where Azure’s Approach Helps
- Enterprise identity
- Entitlement‑aware retrieval becomes easier when identity and access controls flow across services. Consequently, apps ship faster without bespoke auth layers.
- Regional coverage and certifications
- Regulated workloads move faster when regions and attestations already exist. Therefore, procurement cycles shorten.
- Integrated productivity and security suites
- Copilots raise the baseline for internal adoption while analytics unlock insights for decision‑makers. As a result, AI becomes a daily habit, not a side project.
- Marketplace and partner solutions
- Vertical gaps fill quickly through transactable offers that run on the same data and identity rails. Consequently, teams stand up pilots in days, not months.
Common Traps—and How to Avoid Them
- Treating “the model” as the product
- Make the product your workflow, data, and UX. Therefore, swap models without changing the user value proposition.
- Indexing everything
- Curate first; add classification, retention, and redaction before embeddings. Consequently, retrieval stays clean, relevant, and safe.
- Demos without offline evaluation
- Create golden datasets and evaluate each release. Therefore, quality trends become visible and reversible.
- One large model for every task
- Use small or mid‑size models for routing, extraction, and summaries; apply premium models only where they change outcomes. Consequently, cost falls while speed improves.
- Skipping caching and batching
- Add prompt, result, and embedding caches; enable server‑side batching; and stream outputs. Therefore, latency and spend drop together.
A 90‑Day Rollout Plan
Kickoff: Define and focus (Days 1–15)
- Pick one high‑value use case, such as an internal knowledge assistant or a support copilot. Define measurable success (deflection, handle time, CSAT, accuracy). Additionally, agree on guardrails and an exit criterion.
Build: Establish the backbone (Days 16–45)
- Ingest a curated corpus. Implement identity‑aware retrieval, content moderation, and policy checks. Instrument tracing for prompts, retrieved chunks, responses, and token usage. Consequently, you gain visibility early.
Validate: Add evaluation and cost control (Days 46–60)
- Create a golden dataset; track groundedness and correctness. Introduce caching for hot prompts and results. Route light tasks to smaller models and reserve frontier models for complex reasoning. Therefore, spend stabilizes.
Launch: Pilot and decide (Days 61–90)
- Roll out to 50–200 users. Gather structured feedback, iterate retrieval strategies, and A/B test prompts. Publish ROI and make a sober decision: expand, iterate, or end.
Case Study (Anonymized)
Background
A 2,500‑employee B2B SaaS company wanted an internal support assistant. Although documentation lived across SharePoint sites, ticket comments, and internal wikis, agents struggled to find consistent answers. Meanwhile, leadership feared uncontrolled costs and data leakage.
Approach
The team implemented identity‑aware retrieval over a curated corpus, added prompt moderation and answer validation, and logged full traces. They used a small model to classify query intent and a larger model only for generation when necessary. Additionally, they introduced a response cache for popular articles and a nightly job to refresh embeddings after content updates.
Results
Within eight weeks, resolution time dropped 27%, and deflection improved 18%. Because caching and tiered models reduced token use by 43%, the cost per resolved case fell below the baseline knowledge‑base cost. Moreover, audit logs demonstrated that no user accessed content outside their role. Consequently, the CFO approved a phased expansion to customer‑facing support with clear budget gates. Because costs fell while quality improved, leadership approved expansion—another small example of AI accelerating Azure inside the enterprise.
An Executive Checklist
- Strategy
- Define where AI should create measurable value; avoid chasing novelty. Prioritize two or three use cases with clear KPIs.
- Architecture
- Standardize a platform stack: identity‑aware retrieval, orchestration with guards, evaluation, and observability. Therefore, teams stop rebuilding boilerplate.
- Data
- Invest in ingestion quality, lifecycle, deduping, and access controls before indexing. Consequently, retrieval earns trust.
- Security
- Enforce least‑privilege retrieval, policy checks, moderation, and full logging. Review third‑party model risks and keep a model registry.
- Finance
- Stage budgets with optimization gates; set quotas and token ceilings; and report value per currency unit. Kill low‑ROI features fast.
- Product
- Ship thin vertical slices; measure quality continuously; treat prompts and retrieval strategies as code; and iterate based on user feedback.
AI Accelerating Azure: Quick Wins You Can Implement
- Add identity‑aware retrieval to one internal knowledge use case.
- Introduce prompt/result caching and a small‑model router.
- Stand up a minimal evaluation harness with a golden set.
- Log inputs, outputs, tokens, and retrieved chunks for every request.
- Publish a monthly ROI snapshot: cost, quality, and business impact.
FAQs
Does adopting AI on Azure always increase cost?
Not necessarily. Because caching, routing, and smaller models handle many tasks, mature systems often spend less per outcome than manual processes or naive prototypes. Therefore, cost discipline from day one matters more than the platform choice.
What is the fastest way to prove value without risking data?
Start with an internal knowledge assistant over a curated corpus. Enforce identity‑aware retrieval and add a post‑response validator that blocks ungrounded answers. Consequently, you prove value while keeping exposure low.
How do I avoid vendor lock‑in as AI usage grows?
Abstract model calls behind interfaces, store prompts and retrieval policies as code, and maintain a fallback model plan. Therefore, switching providers or mixing models becomes feasible without rewrites.
Which metrics should we track beyond tokens?
Track business outcomes: deflection, handle time, conversion, retention, or cycle‑time. Additionally, track quality: groundedness, exact‑match accuracy, and user satisfaction. Consequently, prioritization becomes evidence‑based.
Where do most projects fail?
Projects fail when teams index everything, skip evaluation, and use one expensive model for all tasks. Fix those three traps—curate data, evaluate continuously, and tier models—and most initiatives succeed.

